Using the Free Trial version of IBM's
Watson Knowledge Studio, I just annotated a text and created a machine learning model in about 3 hours without writing a single line of code. The mantra of WKS is that you don't program Watson, you teach Watson.
For demo purposes I chose to identify personal relationships in Shirley Jackson's 1948 short story
The Lottery. This is a haunting story about a small village and its mindless adherence to an old, and tragic tradition. I chose it because 1) it's short and 2) it has clear person relationships like brothers, sisters, mothers, and fathers. I added a few other relations like AGENT_OF (which amounts to subjects of verbs) and X_INSIDE_Y for things like pieces of paper inside a box.
Caveat: This short story is really short: 3300 words. So I had no high hopes of getting a good model out of this. I just wanted to go through an entire machine learning work flow from gathering text data to outputting a complete model without writing a single line of code. And that's just what I did.
WORK FLOW
I spent about 30 minutes prepping the data. E.g., I broke it into 20 small snippets (to facilitate test/train split later), I also edited some quotation issues, spelling, etc).
It uploaded into WKS in seconds (by simply dragging and dropping the files into the browser tool). I then created a Type System to include entity types such as these:
And relation types such as these:
I then annotated the 20 short documents in less than two hours (as is so often the case, I re-designed my type system several times along the way; luckily WKS allows me to do this fluidly without having to re-annotate).
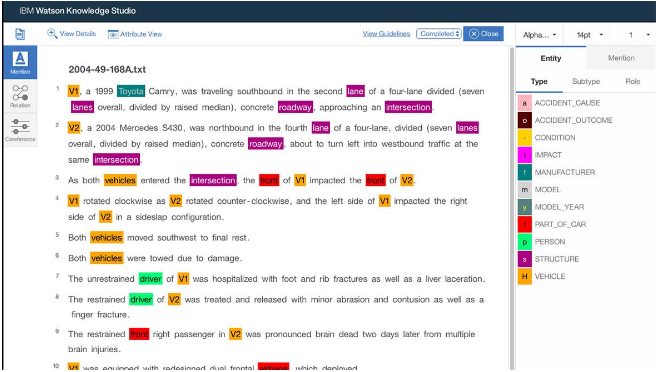
Here's a shot of my entity annotations:
Here's a shot of my relation annotations:
I then used these manually annotated documents as ground truth to teach a machine learning model to recognize the relationships automatically using a set of linguistic features (character and word ngrams, parts-of-speech, syntactic parses, etc). I accepted the WKS suggested split of documents as 70/23/2:
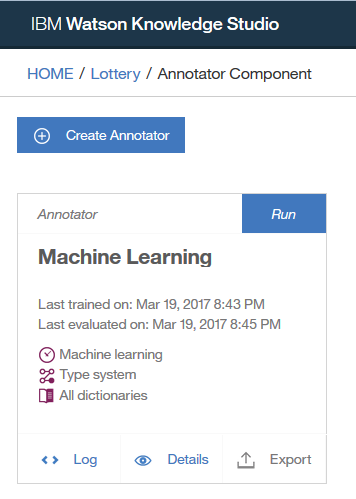
I clicked "Run" and waited:
The model was trained and evaluated in about ten minutes. Here's how it performed on entity types:
And here's how it performed on relation types:
This is actually not bad given how sparse the data is. I mean, an F1 of .33 on X_INSIDE_Y from only 29 training examples on a first pass. I'll take it, especially since that one is not necessarily obvious from the text. Here's one example of the X_INSIDE_Y relation:
So I was able to train a model with 11 entity types and 81 relation types on a small corpus in less than three hours start to finish without writing a single line of code. I did not program Watson. I taught it